
Problem
A global financial services customer had a working AWS proof-of-concept that had been stuck for months. It couldn't move forward: hardened networking missing, no infrastructure-as-code, no CI/CD, ambiguous data flows. The clock mattered. A delivery deadline was weeks away and the project was burning time.
In parallel, their engineers and several business leaders wanted a real grounding in AI engineering: what's genuinely useful, what's hype, and what they could actually build without wasting cycles.
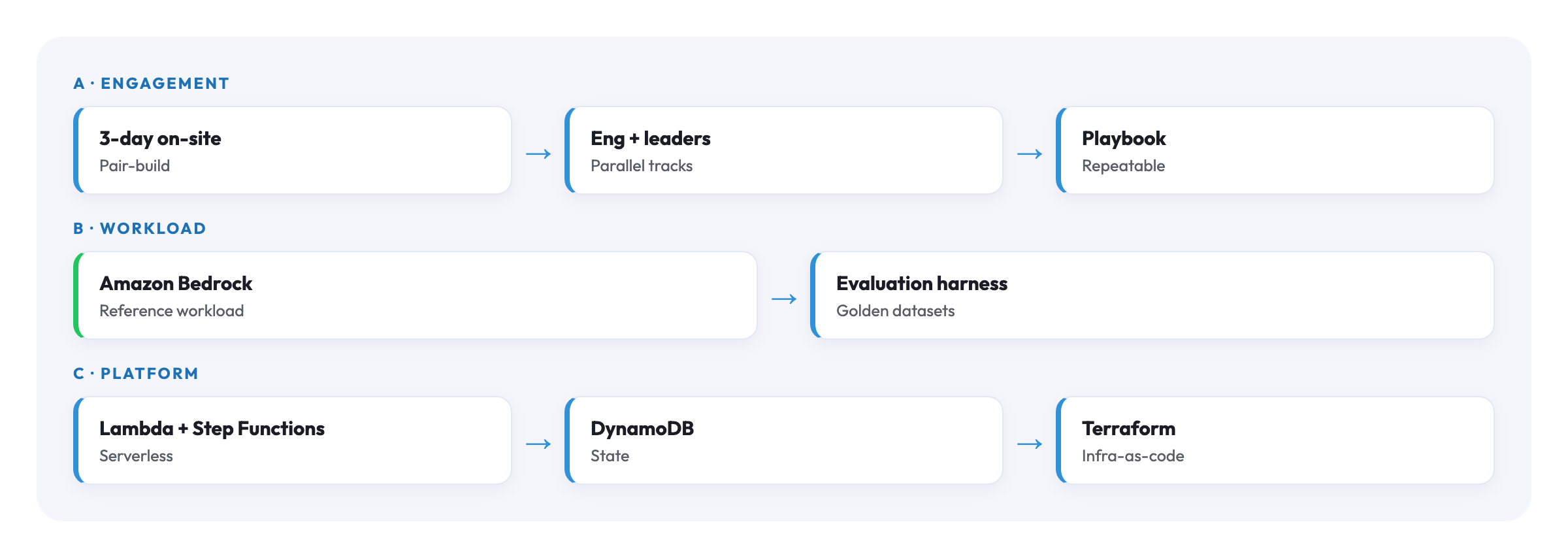
We had three days on-site to do both.
Process
The first decision saved the most money. The PoC team was about to spend roughly six weeks fine-tuning a custom model. Before touching anything, we benchmarked stock Amazon Bedrock against their own data and found accuracy already met the bar, so we cut the fine-tuning work entirely and redirected the effort at what was actually blocking delivery. Deciding what not to build was worth more than any code we wrote that week.
I shaped the rest as a pair-build alongside enablement, not a presentation followed by a workshop.
Day 1: build morning, AI orientation afternoon. Morning: I sat with the customer's two senior engineers and walked the PoC against a readiness checklist covering networking, secrets, observability and data flows, deciding what stayed, what was rebuilt, what deferred. Afternoon: a two-hour session for the wider engineering team on Bedrock, covering what the models do well, what RAG means in practice and where guardrails matter, all hands-on with real prompts.
Day 2: pair-coding. We rebuilt the workload with proper Terraform modules, Step Functions for the long-running orchestration the PoC handled badly, and a CI pipeline. Two of their engineers paired with me throughout; by lunchtime they were leading sections with me reviewing.
Day 3: hardening plus a leadership session. Morning: security review prep, least-privilege IAM, observability, and runbooks for the on-call team. We mock-ran an incident. Afternoon: a closed session with engineering directors and business leaders on where AI investment actually pays back: what to fund and how to staff, concrete, not abstract.
Outcome
The workload went from stuck-for-months to live in three days: hardened, in code, in CI, with the customer's own engineers fluent in every part. They passed their security review the following week. Cutting the unnecessary fine-tuning work saved roughly six weeks of build. Two engineers became the internal champions for the AI work that followed, and the leadership session fed directly into the next year's investment plan.
"Three days moved us further than the previous three months. And we can actually run it ourselves now."
Head of Engineering
Architecture
For engineersTechnical Deep DiveExpand
What the workload actually was
A document-intelligence pipeline: customer documents land in S3 and an EventBridge rule kicks off a Step Functions workflow. A Map state processes each document in turn: Textract handles extraction asynchronously behind a token-bucket throttle, Bedrock classifies it with retries on throttling, a Lambda rules engine validates it, and the result is routed to pass, hold or reject. A separate aggregate state machine rolls the batch into a summary and notifies downstream teams via SNS, while DynamoDB records every state transition as a complete history trail. The architecture diagram above lays out these layers. The PoC version was a single sprawling Lambda with retries hand-rolled; the rebuilt version was structured around the failure modes.
Why Step Functions over a single Lambda
A single Lambda hit three problems on the PoC:
- Long-tail timeouts. Textract async could take minutes; Lambda's 15-minute ceiling meant a percentage of documents always failed.
- No granular retries. Failures in classification re-processed the whole document, wasting Textract spend.
- No visibility. "Where is document X right now?" meant a CloudWatch log search.
Step Functions solved all three. Each state was idempotent, retries were per-step with exponential backoff, and the execution history gave a complete record of every document's journey.
Security posture
Readiness for this customer meant:
- VPC endpoints for every AWS service the workload touched (no internet egress)
- KMS-encrypted DynamoDB and S3, with separate keys per data classification
- IAM roles built from a policy validator's output, not hand-written
- Per-environment Terraform workspaces (dev / staging / prod) with prod behind a separate approval gate
What I deferred
- Multi-region failover. The customer's recovery targets didn't require it yet, and adding it during a 3-day rebuild would have been reckless.
- Custom model fine-tuning. Benchmarking stock Bedrock against their data showed accuracy already met the bar, the call that saved ~6 weeks.
Trade-offs
The pace worked because the customer's engineers were strong and leadership cleared calendars. It would not have worked with a less capable team or stakeholders still in discovery. Honest selling mattered: this wasn't a magic three-day fix, it was an intense pair-build against a clear scope.